
4. 工程的进化:用 PyTorch Lightning 重构#
通过本次任务,你将学会如何使用 PyTorch Lightning 提高开发模型的效率。
4.1. 任务背景#
在上一章,我们使用 PyTorch 成功构建并训练了一个深度神经网络模型。然而,随着项目复杂度的增加,一个标准的训练循环会逐渐变得臃肿——我们需要手动管理训练/验证/测试步骤的切换、记录日志等。这些“样板代码”虽然必要,却分散了我们对模型核心逻辑的注意力,也使得代码的可维护性和可复用性降低。
本章,我们将使用 PyTorch Lightning 框架,来应对上述工程挑战。PyTorch Lightning 并非要取代 PyTorch,而是在其之上提供了一层优雅的抽象,通过将模型、数据、训练逻辑解耦,让代码更清晰、更易维护。我们将用它重构上一章的“风味质检模型”,提高开发模型的效率。
4.2. 最少必要知识#
4.3. 任务鸟瞰#
本次的任务是使用 PyTorch Lightning 框架,重新训练“风味质检模型”。我们将沿用数据准备、模型定义、训练与评估的标准流程来组织内容。为确保实验的可复现性,我们首先进行环境配置。
4.4. 环境配置#
4.4.1. 安装依赖#
!pip install --upgrade dsxllm -i https://pypi.org/simple
4.4.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
4.5. 数据准备#
在传统的 PyTorch 项目中,数据下载、预处理、划分、增强等逻辑常常分散在脚本的不同部分,导致代码难以维护和复用。LightningDataModule 通过将这些步骤封装在一个类中,解决了上述痛点。
使用 LightningDataModule 可以统一管理训练、评估和测试数据。创建 LightningDataModule 的流程如下:
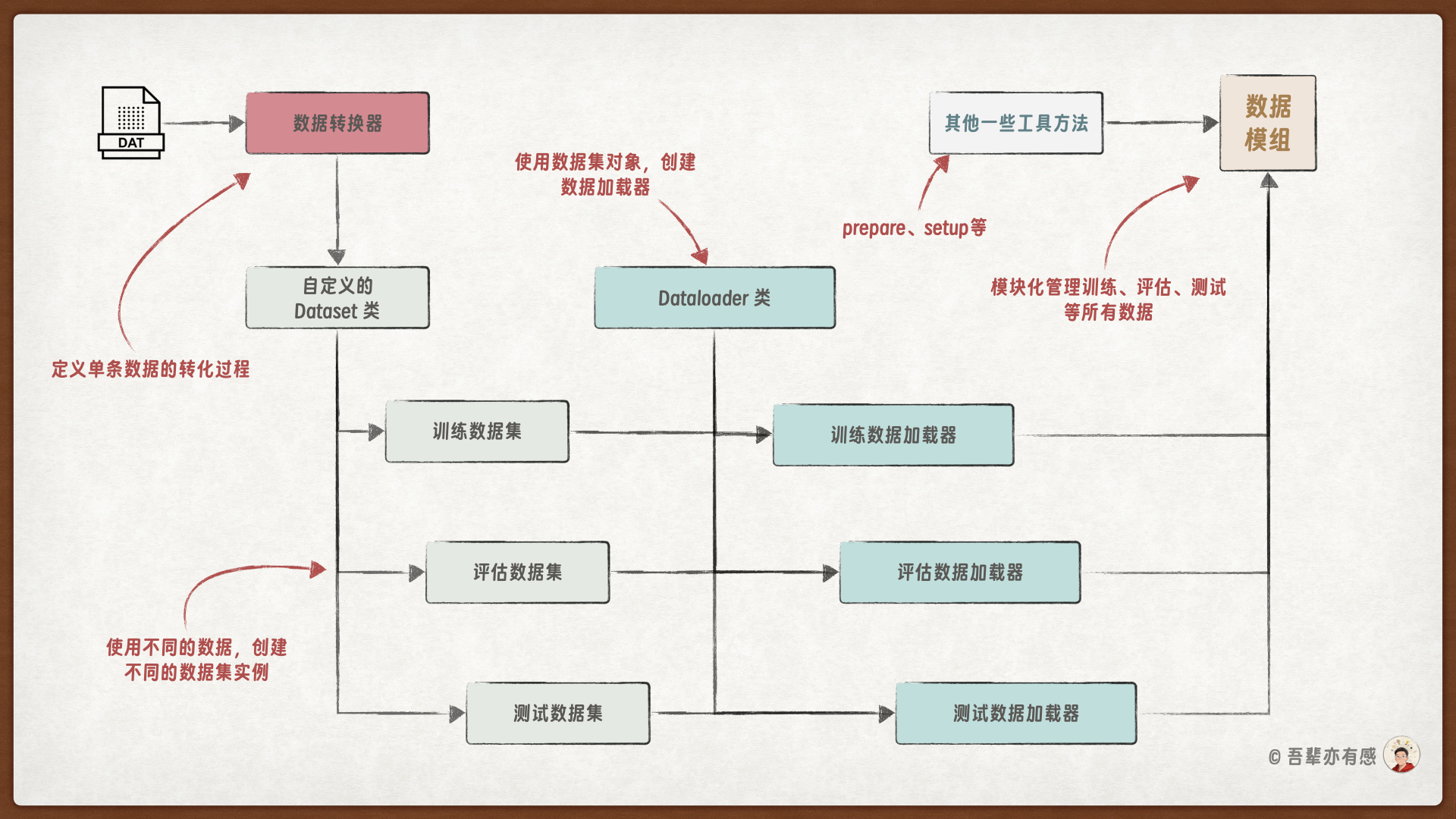
定义数据转换器
自定义数据集类
组装数据模组
4.5.1. 数据集下载#
4.5.2. 定义数据转换器#
将单条数据转化为 <输入特征, 目标标签ID> 数据对。转化处理的流程如下图所示:
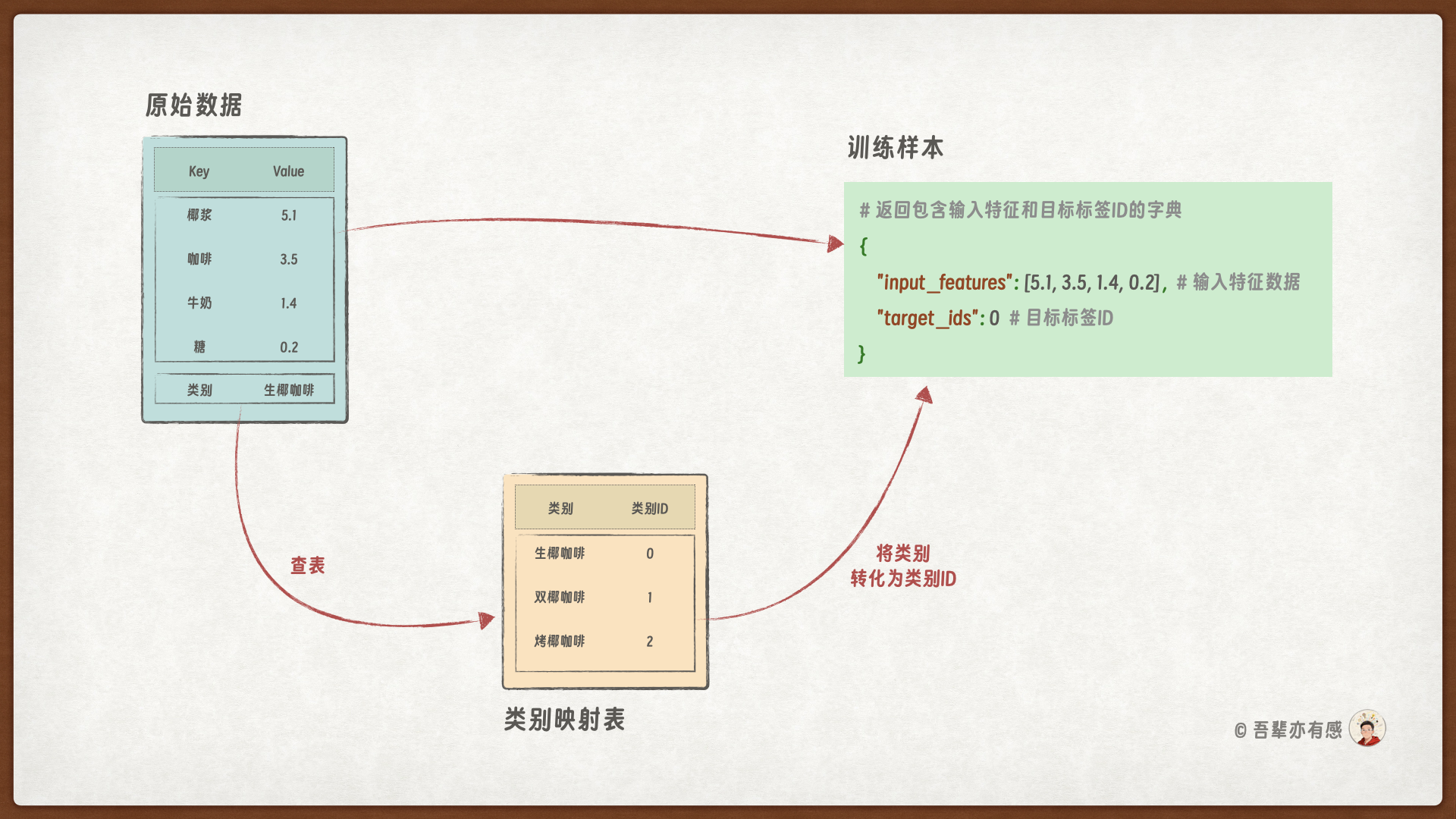
其中 input_features 表示输入特征,target_ids 表示类别对应的ID。
class CoffeeTransform:
def __init__(self, label_to_id):
self.label_to_id = label_to_id
self.id_to_label = {v: k for k, v in self.label_to_id.items()}
def __call__(self, sample):
# 1️⃣ 根据索引获取样本的特征和标签
features, label = sample
# 2️⃣ 将标签转换为对应的ID
label_id = self.label_to_id[label]
# 3️⃣ 返回包含输入特征和目标标签ID的字典
return {
"input_features": features, # 输入特征数据
"target_ids": label_id # 目标标签ID
}
4.5.3. 自定义咖啡分类数据集#
import pandas as pd
from torch.utils.data import Dataset
class CoffeeDataset(Dataset):
"""
自定义咖啡数据集类,继承自PyTorch的Dataset基类
用于加载和处理咖啡分类数据
"""
def __init__(self, samples, transform):
"""
初始化数据集
"""
self.samples = samples
self.transform = transform
def __len__(self):
"""
返回数据集的大小(样本总数)
返回:
- 数据集中的样本数量
"""
return len(self.samples)
def __getitem__(self, index):
"""
获取指定索引的样本数据
参数:
- index: 样本索引
返回:
- 包含输入特征和目标标签ID的字典
"""
# 根据索引获取样本的特征和标签
return self.transform(self.samples[index])
@classmethod
def load_from_csv(cls, file_path, transform):
"""
从CSV文件加载数据的类方法
参数:
- file_path: CSV文件路径
返回:
- CoffeeDataset实例
"""
# 使用pandas读取CSV文件并删除包含缺失值的行
data = pd.read_csv(file_path).dropna()
# 存储处理后的样本
samples = []
# 遍历数据中的每一行
for index in range(len(data)):
# 1️⃣ 获取当前行数据
row = data.iloc[index]
# 2️⃣ 提取特征数据(除最后一列外的所有列),并转换为float32类型
features = row.iloc[:-1].values.astype("float32")
# 3️⃣ 提取标签(最后一列)
label = row.iloc[-1]
# 4️⃣ 将特征和标签作为一个元组添加到样本列表中
samples.append((features, label))
# 创建并返回CoffeeDataset实例
return cls(samples, transform)
4.5.4. 创建 Lightning 数据模组#
LightningDataModule 是 PyTorch Lightning 框架中的一个核心抽象类,它提供了一种标准化、模块化的方式来封装和管理机器学习项目中的所有数据相关操作。通过使用 LightningDataModule,开发者可以将数据处理流程与模型训练逻辑清晰地解耦,从而提升代码的可读性、可复用性和可维护性。
使用 LightningDataModule 标准化处理数据的四步法:
prepare_data()方法:用于下载或准备数据集。setup(stage=None)方法:根据训练的不同阶段(fit,test,predict)来准备数据集。train_dataloader(),val_dataloader(),test_dataloader()方法:分别返回训练、验证和测试阶段的DataLoader对象,定义了数据如何被批量加载、打乱等。teardown(stage=None)方法:用于清理资源,例如在训练、验证或测试结束后释放内存或关闭文件句柄。
import lightning as L
from torch.utils.data import DataLoader
class CoffeeDataModule(L.LightningDataModule):
def __init__(self, transform, batch_size, train_data_file,
val_data_file="", test_data_file=""):
super().__init__()
self.transform = transform
self.batch_size = batch_size
self.train_data_file = train_data_file
self.val_data_file = val_data_file
self.test_data_file = test_data_file
self.train_dataset = None
self.val_dataset = None
self.test_dataset = None
def prepare_data(self):
# 下载或准备数据集的操作(如果需要)
pass
def setup(self, stage=None):
# 加载完整数据集
self.train_dataset = CoffeeDataset.load_from_csv(self.train_data_file, self.transform)
# 加载评估数据集
if self.val_data_file == "":
self.val_dataset = self.train_dataset
else:
self.val_dataset = CoffeeDataset.load_from_csv(self.val_data_file, self.transform)
# 加载测试数据集
if self.test_data_file == "":
self.test_dataset = self.val_dataset
else:
self.test_dataset = CoffeeDataset.load_from_csv(self.test_data_file, self.transform)
def train_dataloader(self):
# 创建训练数据加载器,默认情况下,shuffle=True
return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.val_dataset, batch_size=self.batch_size, shuffle=False)
def test_dataloader(self):
return DataLoader(self.test_dataset, batch_size=self.batch_size, shuffle=False)
4.5.5. 初始化数据模组实例#
初始化数据模组实例,获取训练数据集的数据加载器,并且打印一个批次的数据。
from pprint import pprint
# 创建 CoffeeDataModule 实例并设置
label_to_id = {"生椰拿铁": 0, "双椰拿铁": 1, "烤椰拿铁": 2}
transform = CoffeeTransform(label_to_id)
coffee_datamodule = CoffeeDataModule(transform=transform, batch_size=5,
train_data_file="./dataset/coffee_train.csv",
val_data_file="./dataset/coffee_val.csv")
# 调用 setup 方法初始化数据集
coffee_datamodule.setup()
# 获取训练数据加载器
train_dataloader = coffee_datamodule.train_dataloader()
# 打印一个批次的数据
print("打印一个批次的数据:")
for batch in train_dataloader:
pprint(batch, sort_dicts=False)
break
打印一个批次的数据:
{'input_features': tensor([[4.9000, 3.6000, 1.4000, 0.1000],
[6.1000, 2.6000, 5.6000, 1.4000],
[7.2000, 3.0000, 5.8000, 1.6000],
[6.1000, 2.8000, 4.0000, 1.3000],
[6.9000, 3.1000, 4.9000, 1.5000]]),
'target_ids': tensor([0, 2, 2, 1, 1])}
执行结果和我们直接使用 PyTorch DataLoader 获取的批次数据一致,都包含着输入特征 input_features 和目标标签 target_ids。
4.5.6. 架构对比:散装 vs 模块化#
💡 关键洞察:LightningDataModule 的核心价值在于标准化和模块化,它让数据处理从“临时脚本”变成了“可复用的组件”。
传统 PyTorch DataLoader
代码分散:数据下载、预处理、划分逻辑分散在不同文件或函数中
重复配置:训练、验证、测试需要分别创建DataLoader,容易产生不一致
缺乏标准化:每个项目都有自己独特的数据处理方式
难以共享:数据预处理逻辑难以在不同项目间复用
LightningDataModule
统一封装:将数据处理五步法封装在单一类中
标准化接口:prepare_data、setup、train_dataloader等标准方法
一致性保证:确保训练、验证、测试使用相同的数据处理逻辑
即插即用:可在不同项目间轻松复用和共享
4.6. 重构模型#
4.6.1. PyTorch 开发模型存在的问题#
使用 PyTorch 训练深度神经网络的典型训练循环如下:
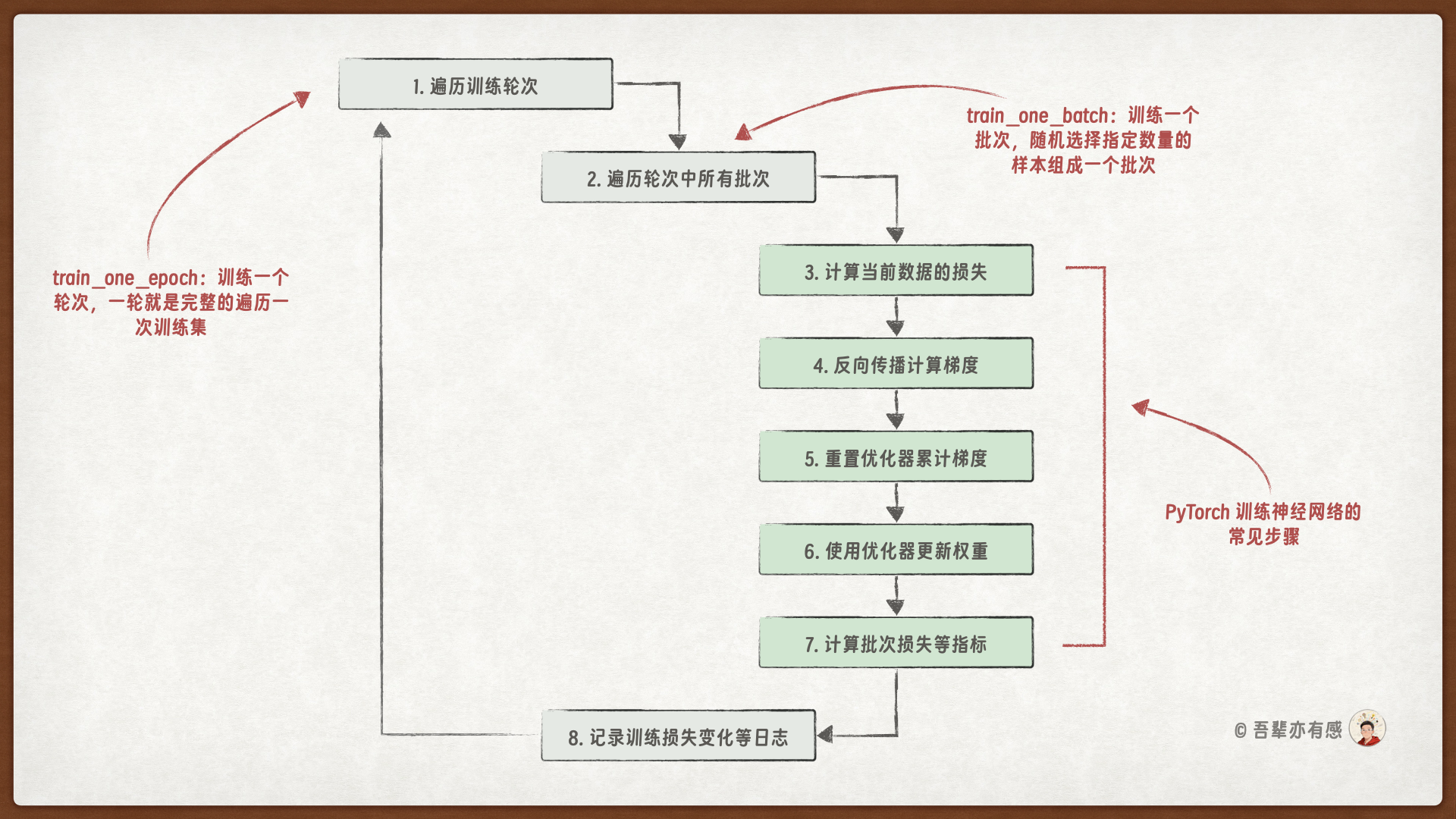
每次训练模型时都重复编写 train_one_batch()、train_one_epoch() 和 train_model() 等方法的代码,这些类似的“样板代码”分散了我们对模型核心逻辑的注意力,也使得代码的可维护性和可复用性降低。所以 PyTorch Lightning 框架提供了一种更简洁的方式来定义模型,它将模型训练逻辑封装在 LightningModule 类中,减少冗余代码,提高可读性和可维护性。
4.6.2. LightningModule 深度解析#
LightningModule 是 PyTorch Lightning 框架的模型模组类,它将深度学习模型的训练、验证、测试和日志记录等逻辑封装在一个类中,让开发者能专注于模型而非工程细节。
你可以把它理解为一个增强版的 PyTorch 模型类。它不仅定义了模型的网络结构,还显式地定义了训练、验证、测试和推理的完整逻辑,以及优化器、学习率调度器等配置。
4.6.2.1. 为什么需要 LightningModule?#
在原生 PyTorch 中,你通常需要自己编写以下代码:
模型定义(nn.Module)
训练循环(for epoch in range(…))
验证/测试循环
损失计算和反向传播(loss.backward())
优化器步骤(optimizer.step())
日志记录(print 或 TensorBoard)
设备管理(.to(device))
检查点保存与加载
分布式训练逻辑
这些代码混杂在一起,会导致:
可读性差:业务逻辑和工程代码纠缠。
可复现性差:实验结构不一致。
难以维护和扩展:修改训练逻辑可能牵一发而动全身。
样板代码多:每个项目都要重写训练循环。
LightningModule 通过一个约定俗成的结构,将上述所有部分清晰地分离,让我们专注于模型的逻辑,而非重复的样板代码。
4.6.2.2. LightningModule 的核心方法#
LightningModule 通过一组标准化的方法接口,将神经网络模型的训练、评估、测试等核心逻辑模块化。每个方法都有明确的职责,这种设计让代码结构清晰且易于维护。我们可以通过重写父类的方法来构建自己的 LightningModule,LightningModule 类图如下:

__init__():定义模型的组件,如网络层、损失函数等(和 nn.Module 一样)。forward(x):定义输入到输出的前向传播逻辑。注意:不要在此方法内计算损失或进行训练。training_step(batch, batch_idx):定义单个训练批次的逻辑,此方法是必需要实现的。validation_step(batch, batch_idx):与 training_step 类似,但用于验证集。此步骤中梯度默认是关闭的。test_step(batch, batch_idx):与 validation_step 类似,但用于测试集。此步骤中,梯度默认是关闭的。configure_optimizers():配置模型使用的优化器和学习率调度器。Lightning 会自动调用优化器的 step() 和 zero_grad()。
除了这些必需方法,LightningModule 还提供了丰富的生命周期钩子(Hooks),如 on_train_start()、on_train_epoch_end()等,允许在训练的不同阶段插入自定义逻辑。
4.6.3. 用 LightningModule 重构 CoffeeClassifier 类#
使用 LightningModule 重构 CoffeeClassifier 类的步骤如下:
在
__init__()中初始化模型的结构、记录训练损失和评估指标的list以及示例输入等。在
forward()实现模型的前向传播逻辑。实现
training_step()方法,定义训练步骤的逻辑。并使用on_train_epoch_end()添加钩子,在每个训练 epoch 结束时自动记录训练损失和评估指标等。实现
validation_step()方法,定义验证步骤的逻辑。并使用on_validation_epoch_end()添加钩子,在每个验证 epoch 结束时自动记录评估指标等。实现
configure_optimizers()方法,配置优化器和学习率。添加
predict()、clear_cache()等自定义方法。
import torch
import lightning as L
from torch import nn
import torch.nn.functional as F
class CoffeeClassifier(L.LightningModule):
def __init__(self, input_size=4, hidden_size=10, num_classes=3, learning_rate=0.01):
super(CoffeeClassifier, self).__init__()
self.learning_rate = learning_rate
# 定义网络层
self.input_layer = nn.Linear(in_features=input_size, out_features=hidden_size)
self.relu = nn.ReLU()
self.output_layer = nn.Linear(in_features=hidden_size, out_features=num_classes)
# 存储每个训练步骤和训练循环的损失
self.train_step_losses = []
self.train_epoch_losses = []
# 用于存储验证步骤的结果
self.validation_step_outputs = []
self.eval_accuracies = []
# 示例输入
self.example_input_array = torch.Tensor(32, input_size)
# 标签id到标签的映射,用于预测解码
self.label_map = None
def forward(self, x):
"""前向传播"""
out = self.input_layer(x)
out = self.relu(out)
out = self.output_layer(out)
return out
def training_step(self, batch, batch_idx):
"""训练步骤"""
input_features = batch["input_features"]
target_ids = batch["target_ids"]
# 前向传播
outputs = self(input_features)
loss = F.cross_entropy(outputs, target_ids)
# 计算准确率
preds = torch.argmax(outputs, dim=1)
acc = (preds == target_ids).float().mean()
# 记录日志
self.log('train_loss', loss)
self.log('train_acc', acc)
# 存储损失以便后续使用
self.train_step_losses.append(loss.detach())
return loss
def on_train_epoch_end(self):
"""在每个训练epoch结束时计算整体损失"""
if self.train_step_losses: # 确保列表不为空
# 计算并记录平均训练损失
avg_train_loss = torch.stack(self.train_step_losses).mean()
self.train_epoch_losses.append({
"epoch": self.current_epoch,
"loss": avg_train_loss.item() # 转换为 Python 数值
})
# 清空列表为下一个 epoch 做准备
self.train_step_losses.clear()
def validation_step(self, batch, batch_idx):
"""验证步骤"""
input_features = batch["input_features"]
target_ids = batch["target_ids"]
# 前向传播
outputs = self(input_features)
# 计算准确率
preds = torch.argmax(outputs, dim=1)
# 保存结果供epoch结束时使用
self.validation_step_outputs.append({'preds': preds, 'labels': target_ids})
def on_validation_epoch_end(self):
"""在每个验证epoch结束时计算整体准确率"""
# 汇总所有预测结果和标签
all_preds = torch.cat([x['preds'] for x in self.validation_step_outputs])
all_labels = torch.cat([x['labels'] for x in self.validation_step_outputs])
# 计算整体准确率
val_overall_acc = (all_preds == all_labels).float().mean()
# 记录整体准确率
self.log('total_samples', len(all_labels))
self.log('total_correct', (all_preds == all_labels).float().sum())
self.log('val_overall_acc', val_overall_acc)
# 将评估结果保存到 eval_accuracies 列表中
self.eval_accuracies.append({
"epoch": self.current_epoch, # epoch编号
"总样本数": len(all_labels), # 验证集总样本数
"正确样本数": int((all_preds == all_labels).float().sum().item()), # 预测正确的样本数
"准确率": round(val_overall_acc.item(), 4) # 准确率
})
# 清空缓存
self.validation_step_outputs.clear()
def clear_cache(self):
"""清除缓存"""
self.train_step_losses.clear()
self.train_epoch_losses.clear()
self.validation_step_outputs.clear()
self.eval_accuracies.clear()
def configure_optimizers(self):
"""配置优化器"""
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
return optimizer
def setup_label_map(self, label_map):
"""根据数据集设置标签映射"""
self.label_map = label_map
def predict(self, features):
"""
对新数据进行预测
Args:
features: 输入特征,可以是单个样本或批量样本
Returns:
predictions: 预测的标签索引
decoded_predictions: 解码后的标签名称
probabilities: 预测概率
"""
# 确保输入是tensor格式
if not isinstance(features, torch.Tensor):
features = torch.tensor(features, dtype=torch.float32)
# 确保模型处于评估模式
self.eval()
# 预测
with torch.no_grad():
outputs = self(features)
predictions = torch.argmax(outputs, dim=1).tolist()
probabilities = torch.softmax(outputs, dim=1).tolist()
# 解码预测结果
decoded_predictions = [self.label_map[pred] for pred in predictions]
return predictions, decoded_predictions, probabilities
def decode_labels(self, label_ids):
"""
将标签ID解码为标签名称
Args:
label_ids: 标签ID列表
Returns:
decoded_labels: 解码后的标签名称列表
"""
if isinstance(label_ids, torch.Tensor):
label_ids = label_ids.tolist()
return [self.label_map[label_id] for label_id in label_ids]
4.6.4. 查看 CoffeeClassifier 模型的详细信息#
创建咖啡分类模型实例,并打印模型摘要:
输入特征维度为
4(椰浆、咖啡、牛奶、糖)隐藏层维度为
10输出类别数为
3(生椰咖啡、双椰咖啡、烤椰咖啡)
# 导入模型摘要工具,用于查看模型的详细结构和参数信息
from lightning.pytorch.utilities.model_summary import ModelSummary
# 创建咖啡分类模型实例
model = CoffeeClassifier()
# 生成模型摘要,max_depth=-1表示显示完整的模型层次结构
summary = ModelSummary(model, max_depth=-1)
# 打印模型摘要信息,包括各层的参数数量、输入输出尺寸等
print(summary)
| Name | Type | Params | Mode | FLOPs | In sizes | Out sizes
-------------------------------------------------------------------------------
0 | input_layer | Linear | 50 | train | 2.6 K | [32, 4] | [32, 10]
1 | relu | ReLU | 0 | train | 0 | [32, 10] | [32, 10]
2 | output_layer | Linear | 33 | train | 1.9 K | [32, 10] | [32, 3]
-------------------------------------------------------------------------------
83 Trainable params
0 Non-trainable params
83 Total params
0.000 Total estimated model params size (MB)
3 Modules in train mode
0 Modules in eval mode
4.5 K Total Flops
使用 ModelSummary 查看模型摘要时,会使用 example_input_array 作为示例输入,调用模型的 forward() 方法生成模型摘要。
从打印的模型摘要信息中可以看到,模型由输入层、激活函数和输出层组成,其中:
输入层
input_layer:将输入特征映射到隐藏层,输入特征维度为 4,隐藏特征维度为 10激活函数
relu:使用 ReLU 激活函数,引入非线性因素,增强模型表达能力输出层
output_layer:将隐藏特征映射到输出类别,隐藏特征维度为 10,输出类别数为 3
4.7. 模型的训练与评估#
模型训练与评估的流程如下:
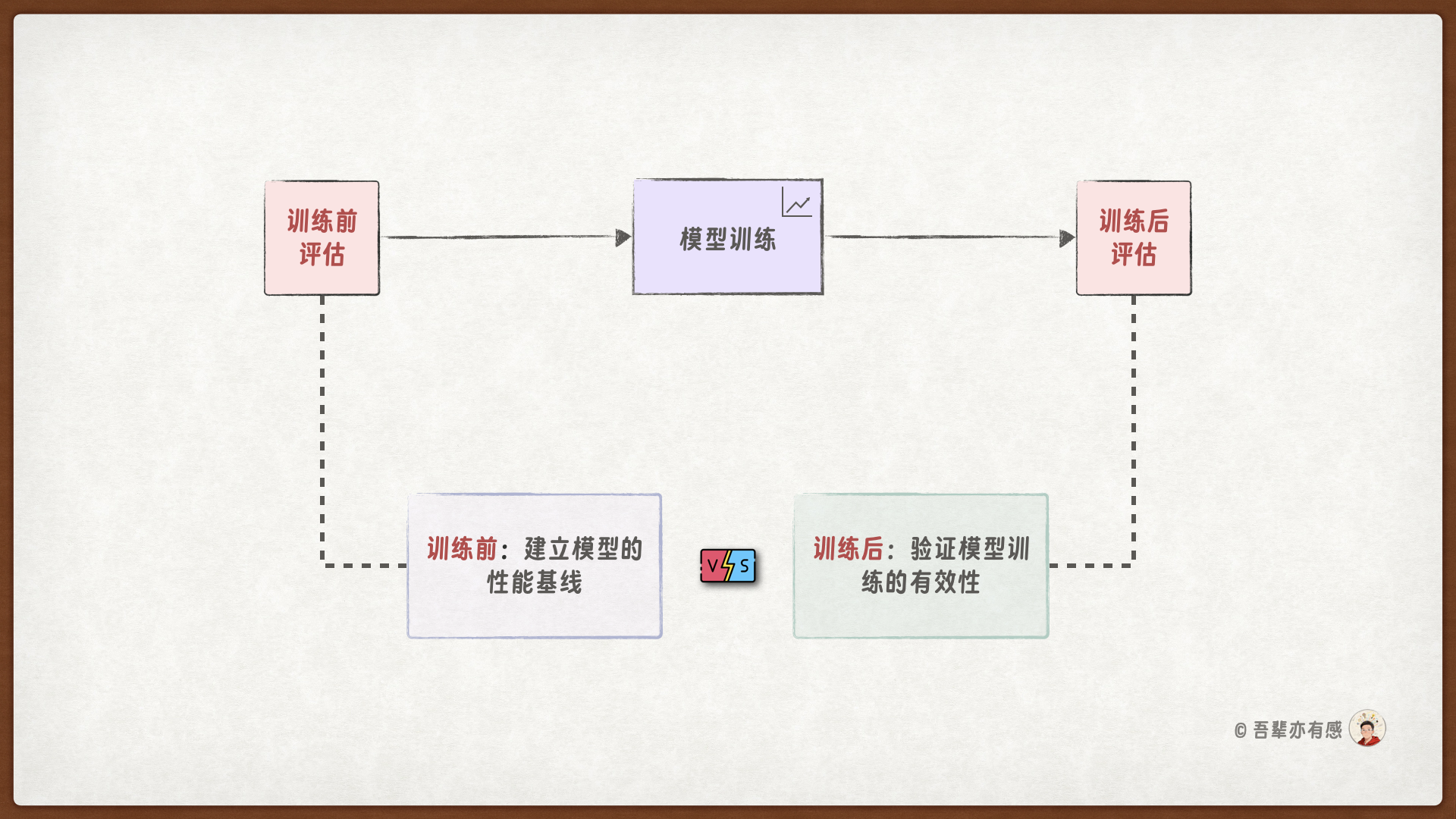
在训练模型之前,先对模型一次评估,以了解模型在训练前的性能。然后再训练模型,在训练完成后,再对模型进行评估,确认训练是否成功。
4.7.1. 训练前评估#
训练前评估为模型性能建立了初始基准,使得后续的训练进度能够被量化追踪。通过对比训练前后的评估结果,开发者可以清晰看到模型的改进幅度,判断训练是否朝着正确的方向发展。
使用 PyTorch Lightning 进行评估时,只需要创建 trainer 实例并设置参数,然后调用 trainer.validate() 函数即可,相对于 PyTorch 简化了很多。
trainer.validate() 会自动使用 validation_step() 对 datamodule 中的验证数据进行评估,并返回验证结果。在评估结束后,on_validation_epoch_end() 方法会被调用,计算并记录整体准确率。
4.7.1.1. 创建 trainer 实例并设置参数#
PyTorch Lightning 的 Trainer 是一个统一管理模型训练评估流程的核心类。它的主要目标是将模型代码与工程代码解耦,从而让开发人员可以专注于模型本身,而不必重复编写繁琐的训练逻辑。
使用Trainer的典型工作流异常简洁,主要包含三个步骤:
准备数据
定义 LightningModule
创建并运行 Trainer
⚙️ Trainer的关键参数详解:
max_epochs:训练的轮数
log_every_n_steps:日志记录的频率
check_val_every_n_epoch:验证的频率
enable_progress_bar:是否显示进度条
# 定义标签到ID的映射关系,将咖啡种类文本转换为ID
label_to_id = {"生椰拿铁": 0, "双椰拿铁": 1, "烤椰拿铁": 2}
# 创建数据变换器,传入标签映射关系用于数据预处理
transform = CoffeeTransform(label_to_id=label_to_id)
# 创建咖啡数据模块,配置数据预处理器、批次大小和数据文件路径
coffee_datamodule = CoffeeDataModule(transform=transform, batch_size=20,
train_data_file="./dataset/coffee_train.csv",
val_data_file="./dataset/coffee_val.csv")
# 创建咖啡分类模型实例:输入维度为4,隐藏特征维度为10,类别数为3,学习率为0.01
model = CoffeeClassifier(input_size=4, hidden_size=10, num_classes=3, learning_rate=0.01)
# 创建PyTorch Lightning训练器,设置训练参数:
# - max_epochs=30: 最大训练轮数为30
# - log_every_n_steps=3: 每3个步骤记录一次日志
# - check_val_every_n_epoch=3: 每3个epoch进行一次验证
# - enable_progress_bar=False: 不显示进度条
trainer = L.Trainer(max_epochs=30, log_every_n_steps=3, check_val_every_n_epoch=3, enable_progress_bar=False)
GPU available: True (mps), used: True
TPU available: False, using: 0 TPU cores
💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
4.7.1.2. 使用 trainer.validate() 进行训练前评估#
# 直接调用验证函数进行训练前评估
trainer.validate(model=model, datamodule=coffee_datamodule)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Validate metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ total_correct │ 10.0 │ │ total_samples │ 30.0 │ │ val_overall_acc │ 0.3333333432674408 │ └───────────────────────────┴───────────────────────────┘
[{'total_samples': 30.0,
'total_correct': 10.0,
'val_overall_acc': 0.3333333432674408}]
在原生 PyTorch 中,评估通常需要编写完整的循环逻辑;而在 PyTorch Lightning 中,评估变得非常简单和结构化,只需调用 trainer.validate() 函数即可。从评估结果中可以看到,在训练之前,模型预测的准确率 val_overall_acc 仅为 33.3%,基本上和随机瞎猜的准确率一致,说明模型在训练前没有任何的预测能力。
4.7.2. 训练模型#
同样,使用 PyTorch Lightning 训练模型也非常简单,只需调用 trainer.fit() 函数即可。
trainer.fit() 会自动使用 train_step() 和 validation_step() 对数据进行训练和验证,并返回训练和验证结果。在训练和验证轮次结束后,on_train_epoch_end() 和 on_validation_epoch_end() 方法会被调用,分别计算并记录训练和验证的准确率。
4.7.2.1. 使用 trainer.fit() 训练模型#
# 清除模型中存储的历史训练损失和评估指标数据,为新的训练做准备
model.clear_cache()
# 使用训练器在指定的数据模块上进行训练
trainer.fit(model=model, datamodule=coffee_datamodule)
┏━━━┳━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓ ┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃ In sizes ┃ Out sizes ┃ ┡━━━╇━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩ │ 0 │ input_layer │ Linear │ 50 │ train │ 2.6 K │ [32, 4] │ [32, 10] │ │ 1 │ relu │ ReLU │ 0 │ train │ 0 │ [32, 10] │ [32, 10] │ │ 2 │ output_layer │ Linear │ 33 │ train │ 1.9 K │ [32, 10] │ [32, 3] │ └───┴──────────────┴────────┴────────┴───────┴───────┴──────────┴───────────┘
Trainable params: 83 Non-trainable params: 0 Total params: 83 Total estimated model params size (MB): 0 Modules in train mode: 3 Modules in eval mode: 0 Total FLOPs: 4.5 K
`Trainer.fit` stopped: `max_epochs=30` reached.
4.7.2.2. 训练过程可视化#
绘制训练过程中损失值的变化曲线,更直观地观察损失值在训练过程中的变化趋势。
from dsxllm.util import plot_loss_curves
# 绘制模型训练的损失曲线
plot_loss_curves(model.train_epoch_losses)
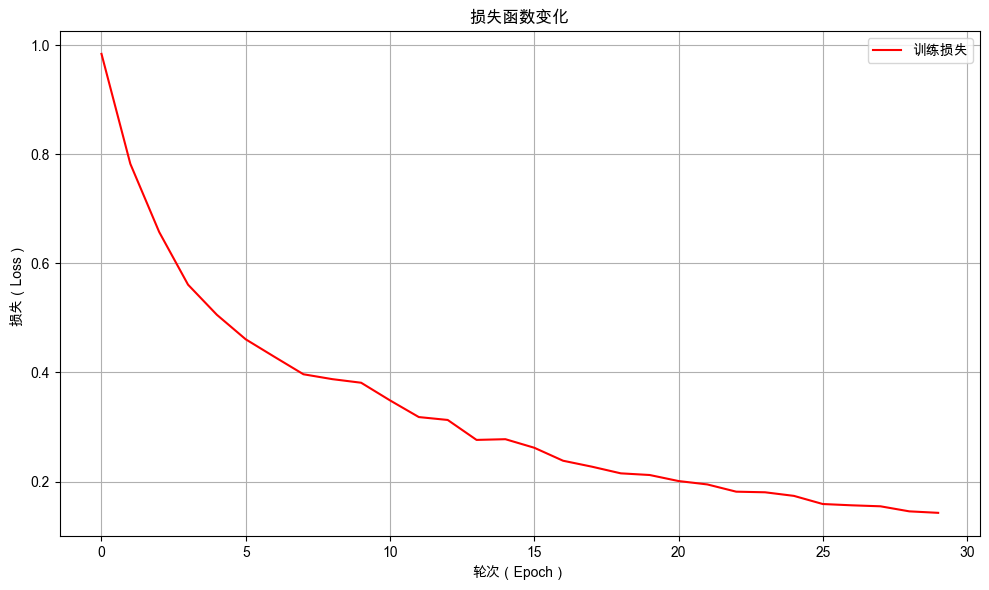
从训练日志中可以看出随着训练的进行,损失值不断下降,表示模型预测准确性不断提高。
4.7.2.3. 查看模型评估记录#
查看训练过程中的评估结果,更直观地观察模型在验证集上的表现。
from dsxllm.util import to_dataframe
# 查看模型训练过程中的评估结果
df = to_dataframe(model.eval_accuracies)
df
| epoch | 总样本数 | 正确样本数 | 准确率 | |
|---|---|---|---|---|
| 0 | 0 | 30 | 10 | 0.3333 |
| 1 | 2 | 30 | 20 | 0.6667 |
| 2 | 5 | 30 | 30 | 1.0000 |
| 3 | 8 | 30 | 30 | 1.0000 |
| 4 | 11 | 30 | 30 | 1.0000 |
| 5 | 14 | 30 | 30 | 1.0000 |
| 6 | 17 | 30 | 30 | 1.0000 |
| 7 | 20 | 30 | 30 | 1.0000 |
| 8 | 23 | 30 | 30 | 1.0000 |
| 9 | 26 | 30 | 30 | 1.0000 |
| 10 | 29 | 30 | 30 | 1.0000 |
4.7.3. 训练后评估#
# 直接调用验证函数进行训练前评估
trainer.validate(model=model, datamodule=coffee_datamodule)
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Validate metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ total_correct │ 30.0 │ │ total_samples │ 30.0 │ │ val_overall_acc │ 1.0 │ └───────────────────────────┴───────────────────────────┘
[{'total_samples': 30.0, 'total_correct': 30.0, 'val_overall_acc': 1.0}]
从评估结果中可以看出,训练前的模型的准确率是 33.3%,训练后的准确率是 100%,说明模型训练非常有效。
4.7.4. LightningModule vs 传统 nn.Module#
通过本次实践,我们已使用 LightningModule 完整实现了模型的训练与评估流程,并亲身体会了其核心特性。LightningModule 继承自 torch.nn.Module,但提供了更高级的抽象层。两者的核心区别在于职责分离:传统 nn.Module 只负责模型定义和前向传播,而 LightningModule 将训练全流程都纳入管理。
特性对比 |
传统 nn.Module |
LightningModule |
|---|---|---|
训练逻辑 |
需手动实现完整训练循环 |
仅需定义 training_step,其余自动处理 |
优化器管理 |
手动创建、调用 optimizer.step() |
configure_optimizers() 定义后自动调用 |
设备管理 |
需手动调用 .cuda() 或 .to(device) |
自动处理,无需显式设备转移 |
分布式训练 |
需手动配置D istributedSampler |
Trainer 自动处理分布式采样 |
日志记录 |
需手动集成 TensorBoard 等 |
self.log() 自动记录并集成多种日志工具 |
4.8. 使用模型进行预测#
模型训练完成后,可以使用训练好的模型对新的数据进行预测。模型预测的步骤如下:
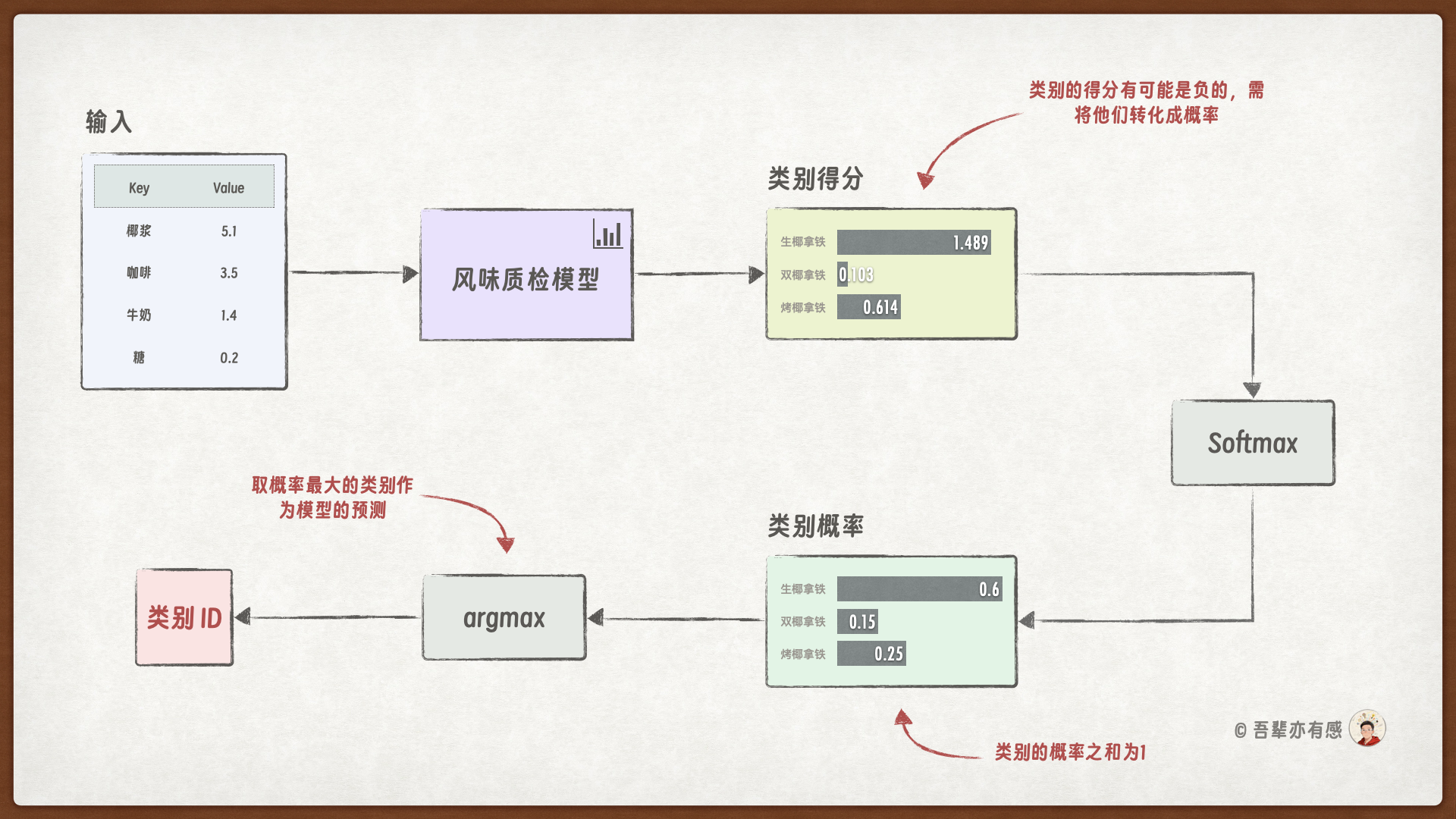
在预测阶段和训练时不太一样,预测阶段需要使用 softmax() 将模型预测的类型得分转换为概率,并使用 argmax() 选择概率最大的类别 ID 作为预测结果。预测阶段不需要进行反向传播,因此可以设置 torch.no_grad() 来关闭梯度计算,提高预测效率。
from dsxllm.util import print_classification_predictions
# 初始化各类别的标签到ID的映射关系(需要和训练模型时一致)
label_to_id = {"生椰拿铁": 0, "双椰拿铁": 1, "烤椰拿铁": 2}
id_to_label = {v: k for k, v in label_to_id.items()}
# 1️⃣ 假设我们有几个新的咖啡样本,每个样本包含[椰浆, 咖啡, 牛奶, 糖]四个特征
new_samples = [[4.4, 2.9, 1.4, 0.2], [6, 2.9, 4.5, 1.5], [6.9, 3.2, 5.7, 2.3]]
# 定义这些样本对应的真实标签
true_labels = ["生椰拿铁", "双椰拿铁", "烤椰拿铁"]
# 将真实标签转换为对应的ID
true_label_ids = [label_to_id[label] for label in true_labels]
# 2️⃣ 设置模型标签映射关系
model.setup_label_map(id_to_label)
# 3️⃣ 使用训练好的模型对每个样本进行预测
predictions, decoded_predictions, probabilities = model.predict(new_samples)
# 4️⃣ 输出最终的分类预测结果,包括准确率统计和详细对比
print_classification_predictions(new_samples, true_label_ids, predictions, probabilities, id_to_label)
🎯 分类预测结果 (准确率: 3/3 = 100.00%):
+----------------------+----------+----------+----------+------+
| 输入 | 真实标签 | 预测标签 | 最高概率 | 标记 |
+----------------------+----------+----------+----------+------+
| [4.4, 2.9, 1.4, 0.2] | 生椰拿铁 | 生椰拿铁 | 0.9845 | ☑ |
| [6, 2.9, 4.5, 1.5] | 双椰拿铁 | 双椰拿铁 | 0.8321 | ☑ |
| [6.9, 3.2, 5.7, 2.3] | 烤椰拿铁 | 烤椰拿铁 | 0.8970 | ☑ |
+----------------------+----------+----------+----------+------+
从结果中我们可以看到,模型在所有测试样本上都做出了正确预测。但是,对每一个样本模型的置信度仍然存在差异,尤其是样本2的预测概率相对较低,说明模型对这个样本的分类相对不够确定,表示模型对预测的结果不够自信。
4.9. 本章小结#
本章的核心成果是使用 PyTorch Lightning 对咖啡风味质检模型进行了工程化重构。我们通过 LightningDataModule 标准化了数据管理,通过 LightningModule 将训练、验证逻辑解耦并模块化,并统一交由 Trainer 驱动训练与评估流程。此次重构的核心价值,不仅在于通过职责分离消除了繁复的样板代码,更在于为我们节省了宝贵的开发时间与维护成本。
4.10. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。